关于大语言模型使用技巧与API工具使用的个人笔记
提示工程
为什么要了解提示工程
同样的提问意图,在不同的提问策略下可以得到有显著差异的结果,有技巧地提问更能期待大模型得到更高质量的回答。所谓的高质量回答体现在:
-
挖掘出模型的潜在知识和能力
-
使模型更准确地理解输入的问题或任务,并提供相关回答
-
改进模型的生成输出,提高可读性、连贯性和准确性
提示工程的指导原则
简单总结一些影响大模型回答质量的重要因素/技巧(其中部分技巧可能会随着大模型迭代升级而变得没那么重要,但从思维方法论的角度来说也值得践行)
-
提问具体明确不含糊
-
举例引导期望的答案
3R
-
Role:角色设定和目的,确定大模型以什么样的身份完成任务。如企查查知彼阿尔法定位商查大模型,可查商业相关信息(企业、供应商相关工商、招聘、专利、舆情等信息)
-
Result:期望的结果。希望大模型输出什么样的结果,结果包括什么内容、有哪些特点或约束。可参考OKR(职场目标与关键成果)的SMART要求:
-
Specific,清晰具体的语言为对话定义明确的焦点,确保大模型理解当前主题和任务
反例:你对xxx报告的看法 正例:xxx报告的结论是否被xxx特点的人广泛接受,有哪些赞同或反对的声音反例:简单易懂 正例:用短语,不用专业术语,xx句/词以内 -
Measurable,提供可衡量的约束条件,如数字、客观标准
反例:对于xxx, 要有权威论证 正例:对于xxx,要有xxx行业/研究所的专家的观点 -
Relevant,相关联的,对结果的描述要与角色设定、背景目的保持一致,体现相关性。
-
-
Recipe,思考如何才能拿到预期的结果,并给出方法和指导。对于复杂的、独特的任务,可以给出示例,帮助大模型进行任务拆解,通过思维链的方法进行问题拆解(大问题拆为小问题),以逻辑清晰的方式组织问题或步骤,引导大模型沿着特定的思考路径以更系统、更连贯的方式回答问题。
当然,大模型原有知识可能不足以提供复杂任务所需要的数据支撑,在数据/知识源不充足的情况下, 即便采用思维链的方法大模型也无法得出最终结果,但至少可以在问题拆解后给出更具体的问题解决思路/更丰富的逻辑框架。
示例1:
问题:深圳有多少渣男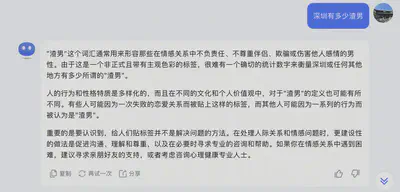
问题:深圳有多少渣男
思路:这是一道市场规模估算题,目的是考察逻辑能力、分析能力、计算能力。该问题没有标准答案但有标准套路。
步骤:1. 界定问题:明确问题范围和假设,如指定的地域指哪个行政区,目标对象指哪些类型
2. 分解问题:将问题分解为若干子问题或模块,例如按照不同地区、不同密度和比例划分
3. 估算数据:对每个子问题或模块进行合理假设和估算,如利用已知数据、常识判断、类比推理等方法得出每个模块的数量或比例
4. 汇总结果:将所有子问题或模块的结果相加或相乘,得出最终答案,并检查是否合理和一致
5. 总结思路:简要回顾整个解题过程,并指出可能存在的不确定性和改进空间。
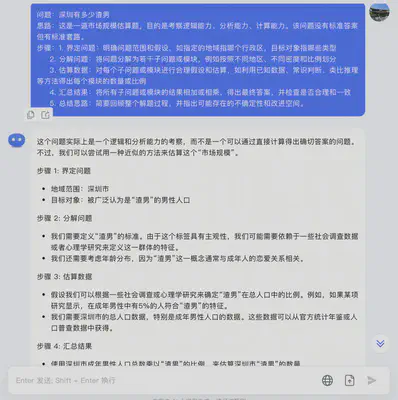

问答示例
询问旅游/游玩地点


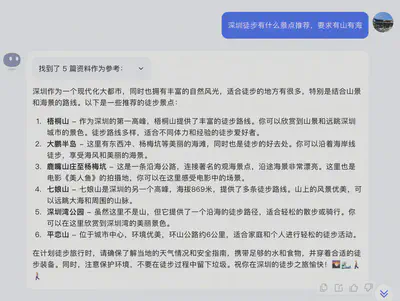
询问美食相关
大模型开放平台
国内大模型列表:
-
智谱AI
-
MoonShot Kimi
-
文心一言
-
盘古大模型
-
……
国外大模型列表:
-
ChatGPT
以下示例均基于Python
星火大模型
官方提供了简单的demo脚本,可自行稍加改造封装成一个组件。
输入: 你是一个专业导游,对惠州罗浮山非常熟悉,请给出罗浮山3日游攻略,大于500字小于1000字
星火大模型V2.0

可以看到,星火大模型V2在回答上述问题时出现了事实错误,其介绍的“罗浮宫”并不存在。
智谱AI
pip install zhipuai
用户输入:
如何学习Spark,请给出学习计划
GLM4:
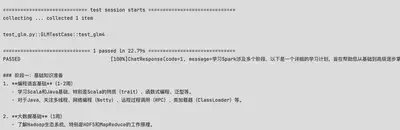
============================== 1 passed in 22.79s ==============================
PASSED [100%]ChatResponse(code=1, message=学习Spark涉及多个阶段,以下是一个详细的学习计划,旨在帮助您从基础到高级逐步掌握Spark。
### 阶段一:基础知识准备
1. **编程语言基础**(1-2周)
- 学习Scala和Java基础,特别是Scala的特质(trait)、函数式编程、泛型等。
- 对于Java,关注多线程、网络编程(Netty)、远程过程调用(RPC)、类加载器(ClassLoader)等。
2. **大数据基础**(1周)
- 了解Hadoop生态系统,特别是HDFS和MapReduce的工作原理。
- 学习数据存储和数据处理的基本概念。
### 阶段二:Spark基础入门
1. **Spark框架理解**(1周)
- 理解Spark是什么,以及它的应用场景,如批处理、流计算、图计算等。
- 了解Spark与Hadoop的区别及Spark的优势。
2. **API使用**(2周)
- 学习RDD(弹性分布式数据集)的基础操作,包括transformation和action。
- 掌握SparkSession的创建及使用,学习DataFrame和Dataset API。
3. **运行模式**(1周)
- 熟悉Spark的本地运行模式,Standalone集群模式,以及Spark on Yarn的部署和运行。
### 阶段三:深入理解Spark Core
1. **任务调度与执行**(2周)
- 学习Spark的任务提交过程、任务调度和执行原理。
- 理解宽依赖和窄依赖,以及lineage机制。
2. **性能调优**(2周)
- 学习Shuffle操作及其优化。
- 掌握Spark中的缓存机制,理解何时以及如何使用缓存。
### 阶段四:高级特性与优化
1. **Spark SQL**(2周)
- 学习Spark SQL的使用,包括Hive兼容性、DataFrame和Dataset的转换。
- 探索Spark SQL的优化策略,如查询优化、执行计划等。
2. **Spark Streaming**(2周)
- 理解Spark Streaming的基本概念和架构。
- 学习如何构建实时数据处理应用,包括窗口操作、状态管理。
3. **其他模块**(1-2周)
- 学习图计算(GraphX)和机器学习库(MLlib)的基础。
- 了解Spark的扩展库,如Structured Streaming和PySpark的新特性。
### 阶段五:实战与源码阅读
1. **实战项目**(3-4周)
- 完成一个或多个Spark项目,实践之前学习的理论知识。
2. **源码阅读**(4周以上)
- 选择Spark的部分模块进行源码阅读,理解其内部实现机制。
### 阶段六:持续学习与社区参与
- 跟进Spark的最新版本更新和社区动态。
- 参与社区讨论,尝试解决GitHub上的问题。
- 持续学习,实践是检验真理的唯一标准。
Moonshot AI
参考Moonshot AI - 开放平台,API调用非常简单,支持非流式请求和流式请求。
可以简单复用openai库.
pip install openai
from openai import OpenAI
from prompts.prompt_template import GastRole
MOONSHOT_API_KEY = "xxxxxxxxxxx"
client = OpenAI(
api_key=MOONSHOT_API_KEY,
base_url="https://api.moonshot.cn/v1",
)
model="moonshot-v1-8k"
question = "从外地来深圳,不想吃辣椒"
prompt_messages = GastRole.prompt_messages
prompt_messages.extend([
{"role": "user", "content":question}])
completion = client.chat.completions.create(
model=model,
messages=prompt_messages,
temperature=0.3,
)
message = completion.choices[0].message
print(f"Question: {question}")
print(f"Answer: {message.content}")
示例:让大模型扮演一个职业规划顾问


示例:让大模型扮演一个美食家


零一万物大模型
除文字问答外,支持视觉问答。
示例:NL2SQL
from openai import OpenAI
API_BASE = "https://api.lingyiwanwu.com/v1"
API_KEY = "xxxxxxxxxx"
client = OpenAI(
api_key=API_KEY,
base_url=API_BASE
)
question = "你的自然语言转SQL能力如何?我来考你一个问题,在PostgreSQL数据库中,我有一个企业数据表company,希望你帮我查出注册资本(reg_cap)大于5000万人民币, 行业(industry)为互联网,通信地址在深圳西丽地铁站方圆500米的企业。"
completion = client.chat.completions.create(
model="yi-34b-chat-0205",
messages=[{"role": "user", "content": question}]
)
print(completion.choices[0].message.content)
下图为问答结果,可以看到生成的SQL语句在语法上没有问题,实际应用时可通过提示指明字段的说明让SQL更加精确。

示例:视觉问答
curl --location 'https://api.lingyiwanwu.com/v1/chat/completions' \
--header 'Authorization: Bearer $API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"model": "yi-vl-plus",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "xxxxxxxx"
}
},
{
"type": "text",
"text": " 请总结图片内容,针对性地给出建议,需要考虑你给建议的对象是谁,他需要什么样的建议。"
}
]
}
],
"stream": false,
"max_tokens": 1024
}'

curl --location 'https://api.lingyiwanwu.com/v1/chat/completions' \
--header 'Authorization: Bearer $API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"model": "yi-vl-plus",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "xxxxx"
}
},
{
"type": "text",
"text": " 请总结图片内容,揣摩图片内容撰写者的身份,动机"
}
]
}
],
"stream": true,
"max_tokens": 1024
}'

场景
利用大模型的基础能力,完成一些基础NLP任务
问题分类/意图识别
prompt:
PROMPT = {
"ticket_question": {
"name": "票务问答",
"description": "查询或预定车票、船票、机票等,关于票务类交通工具班次类问题。"
},
"food_question":{
"name": "美食问答",
"description": "查询美食,食品"
},
"travel_question":{
"name": "旅游问答",
"description": "查询旅游景点、游玩地,包括热门景点和冷门景点,或者具有特殊性的地方。"
},
"other_question":{
"name": "其他问答",
"description": "不明确的问题"
}
}


关系抽取
PROMPT = [
{
"document": "郭靖和黄蓉是情侣,欧阳克追求过黄蓉,欧阳锋呢?",
"entities": ["郭靖", "黄蓉", "欧阳克", "欧阳锋"],
"relation": [("郭靖", "情侣", "黄蓉"),
("黄蓉", "追求者", "欧阳克")
]
}
]
- 基于零一万物的模型yi-34b-chat-0205

- 基于月之暗面的模型Moonshot 8k

可以看到,当给出一些不合事实的文档,月之暗面的模型能够更好地鉴别反事实现象并给出解释。
通用流程
-
数据收集
-
数据清洗和预处理
-
数据表示(可直接使用文字,也可进行嵌入表示,如将文本嵌入向量空间,除方便大规模分析之外,也可提高数据集安全性)
-
应用(根据业务需求构造prompt支持下游任务,针对prompt还可引入指令优化)