认识数据驱动的测试
0x00 前言
之前的文章简单介绍了自动化测试,在自动化测试平台中,有一个重要的组件或概念称为“数据驱动的测试(Data Driven Tests, DDT)”,其目的是将测试脚本与测试数据分离,本质上是测试逻辑的解耦,使得测试流程的代码编写与测试过程中所使用的数据/用例设计可以分别进行。
数据驱动的测试解决了如下痛点:
对于同一份测试代码,测试数据可能会发生大量变化,如果测试数据与代码耦合可能会为代码维护带来不必要的麻烦或增加不必要的代码编写。
框架
以基于Python语言的DDT框架为例介绍DDT的主要模块功能与模块关系。
DDT主要有三大部件:
-
数据源
csv、excel、json、xml等
-
数据加载脚本
将数据源读取到内存中(特定的数据结构)
-
测试脚本
读取数据变量,进行测试,保存测试信息。
0x01 简单示例
结合ddt的单元测试
通过@data装饰器对测试数据进行测试
from ddt import ddt, file_data
import unittest@ddt
class TestBgeLargeEncoder(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.pipeline = ReportGeneratePipeline(article_gen_lm=article_gen_lm,
article_summary_lm=article_summary_lm,
article_style="bullet")
cls.outline_input = get_default_outline()
cls.information_table = NewsInformationTable(news_information,
encoder=SentenceTransformer(DEFAULT_ENCODING_MODEL))
cls.information_table.prepare_table_for_postprocess()
@data("人工智能", "AI", "神经网络")
def test_01_initialize(self, query):
result = TestBgeLargeEncoder.information_table.retrieve_information_plus([query])
print(f"Query {query}: got {[r.title for r in result]}")
self.assertIsInstance(result, list )

通过文件存储测试数据
示例场景:某同学设计了一个摘要算法,需要用一批新闻数据批量测试摘要算法的效果。
测试步骤实现:
-
准备测试数据(比如用json文件组织)
-
准备测试脚本
from ddt import ddt, file_data import unittest import logging import abstract_summary logging.basicConfig( level=logging.DEBUG, # 设置日志级别为 DEBUG format='%(asctime)s - %(levelname)s - %(threadName)s - %(funcName)s- %(lineno)d - %(message)s', # 定义日志格式 datefmt='%Y-%m-%d %H:%M:%S' # 定义日期时间格式 ) logger = logging.getLogger(__file__) SENTENCE_COUNT = 3 test_data_path = "datasource/test.json" @ddt class SummaryTestCase(unittest.TestCase): @file_data(test_data_path) def test_summary_from_files_01(self, title, content, abstract, **kwargs): if self.summrier_proxy is None: logger.warning("None summarier") else: result = self.summrier_proxy.summarier_text(content) logger.debug(f"{title}: {result}") # self. self.assertIsInstance(result, str) self.abstract = result msg = f""" Title: {title}\n Abstract: {result}\n Current_Abstract: {abstract} """ self.assertLess(len(self.abstract), 300, f"Abstract length: {len(abstract)}\n{msg}") self.assertEqual(2, 1, msg) ```python @ddt class LSASummaryTestCase(SummaryTestCase): @classmethod def setUpClass(cls): cls.summarier = abstract_summary.LsaSummarizer() cls.summrier_proxy = abstract_summary.TextSummaryProxy(summarier=cls.summarier, sentences_count=SENTENCE_COUNT) if __name__ == '__main__': unittest.main() -
运行测试用例
可以看到,简单地通过@ddt类装饰器可以让TestCase类支持数据驱动的测试,通过@data装饰器可以很方便地使用不同数据执行用例。通过@file_path装饰器可以将文件中的数据作为参数执行测试用例。
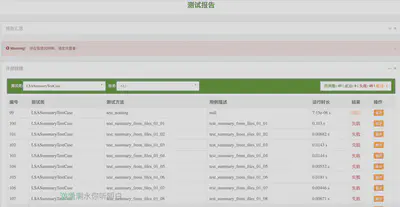
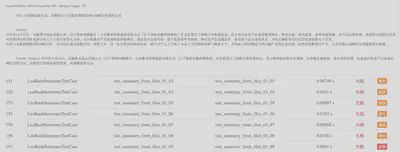
ddt结合第三方库生成测试报告
举例来说,可以使用BeautifulReport生成报告。
# ...省略...
if __name__ == '__main__':
suite = unittest.TestSuite()
from . import test_filter
tests = unittest.TestLoader().loadTestsFromModule(test_filter)
suite.addTests(tests)
report = BeautifulReport(suite)
report.report(description="检索", report_dir=".",
filename=f"各类检索策略对比-{REMOVE_DUP}-latest1.html", theme='theme_cyan')
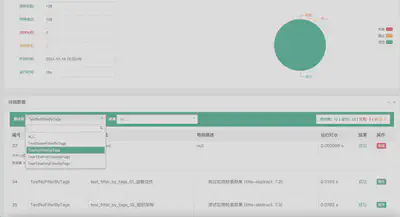
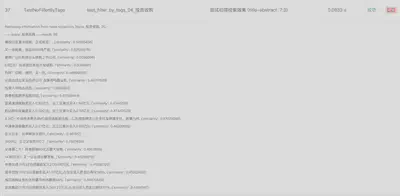
要点
基于DDT的思想,我们可以将测试数据(包括输入、输出和预期结果)都进行持久化存储,高效地将测试数据送入测试用例中。由于对测试数据和测试代码进行了解耦,测试代码也将更具有可维护性。