Postgresql vs Mysql
资料
Postgres
MySQL
一些说法
-
Oracle有才无德
-
MySQL才浅德薄
-
PostgreSQL德才兼备
概念
对象关系型数据库
面向对象的特性
关于MySQL
-
MySQL有哪几种存储引擎?各自有什么优缺点?适用场景是?
-
MySQL索引的工作机制
-
MySQL性能优化方式
-
MySQL分库分表
-
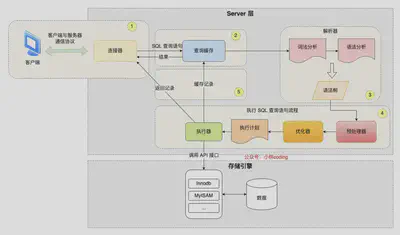
SQL执行过程
索引
索引是为了加速数据查询的数据结构,让我们能够以尽可能少的操作次数查到想要的数据。现实中的字典可按拼音/部首查字,拼音表、部首表就是字典中的索引。对于数据库查询而言,什么样的数据结构能够让我们查找数据时尽可能减少磁盘IO次数呢?一种经典的思路就是将数据通过平衡的多路搜索树进行组织,比如B-Tree(Balance Tree)、B+Tree。
B-Tree
B-Tree即平衡树,是所有的叶子节点都在同一层的多路查找树。
B+Tree
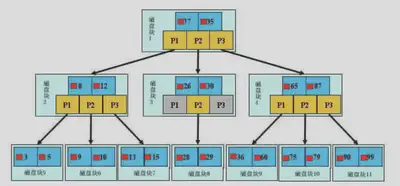
B+树的查找过程
先读取根节点磁盘块到内存中,通过二分查找确定待查找数据项在哪个子节点磁盘块中,然后将对应子节点磁盘块加载到内存中进行二分查找缩小范围,依此类推,直到在某个叶子节点磁盘块中找到目标,结束查询。
所以需要的磁盘IO次数就是树的高度。
-
为什么要把数据放到叶子节点?
非叶子节点可以存放更多索引,数据量相同的情况下,B+树结构会比B树更加“矮胖”,提高查询效率。删除数据时不会引起树结构的复杂变形。
B+树与B树的性能对比
-
单数据查询
-
插入、删除效率
B树删除根节点时,可能导致树发生很大的变形
-
范围查询
由于B树的数据可能在非叶子节点中,要实现范围查询只能通过树的遍历,涉及多个磁盘IO操作;而B+树的数据存在叶子节点中,叶子节点间又通过指针构成了有序双向链表,因此范围查询效率更高。
索引的建立原则
对区分度高的字段建立索引,区分度公式:count(distinct FIELD)/count(*)
索引在什么情况下可能失效
-
对索引使用左或左右模糊匹配
-
对索引使用函数
索引指对数据原始值建立索引,而非对数据经函数处理后的结果建立索引。MySQL8.0之后支持函数索引特性,可以针对函数计算后的值建立索引。
-
对索引进行表达式计算
原理与对索引使用函数类似。
-
对索引进行隐式类型转换
分情况讨论,如果索引字段是字符串类型,但条件查询中的输入参数是整型,会走全表扫描。
如果索引字段是整型,条件查询中输入参数是字符串类型时,索引不会失效,因为MySQL会将字符串转为整型。
-
联合索引非最左匹配
对主键字段建立的索引叫聚簇索引,对普通字段建立的索引叫二级索引。多个普通字段组合在一起建立的索引叫联合索引/组合索引。
联合索引的建立顺序会影响查询性能,因为联合索引是按照最左优先的顺序进行索引匹配。
-
WHERE子句中的OR
如果存在OR查询,其中一个条件的字段没有建立索引,那么数据库会走全表扫描,因为OR查询意味着需要查询OR连接的两个条件的结果集的并集。
事务
-
事务的隔离级别如何实现?
-
事务有哪些特性?
-
并行事务会引发什么问题?
SQL执行过程