Python内存管理基础及性能优化技巧
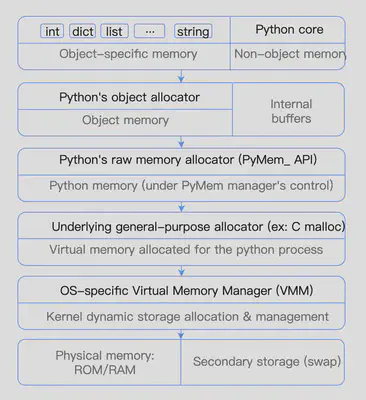
Python内存管理机制
python解释器在系统级内存分配器和C语言内存分配器之上封装了自己的内存分配器,包括:
-
一个底层的对象分配器(raw memory allocator)进行底层的内存管理。
-
对象特定的内存分配器
对于特定的对象,如int、dict、list等会使用对象特定的内存分配器;对于自定义对象和一些不具有特定对象分配器的对象,会使用通用的python对象分配器分配内存。
Python中的垃圾回收是如何完成的?
以引用计数为主,标记-清除、分代回收为辅。
-
引用计数
python虚拟机会为每个对象维护一个引用计数,当你对对象创建了新的引用(比如赋值、参数传递、添加到容器中),引用计数会增加。将对象作为参数传递给函数时,会增加临时引用。当引用被销毁时(如通过del删除引用),引用计数会减少,当对象的引用计数为0时,垃圾回收器会立即回收对象所占资源。
通过sys.getrefcount可以获取对象的引用计数。
-
标记-清除
引用计数无法处理循环引用的问题,因此python还会通过标记-清除算法清理具有循环引用的“垃圾”对象。基本原理如下:垃圾回收模块会定期扫描python中的对象,“标记”阶段会从根对象开始遍历,找到所有“可达”对象,如果发现对象间存在循环引用现象,则会为循环引用的对象引用计数减1,标记阶段结束后,仍然存在引用的对象称为“可达”对象,可以理解为存活对象,有用的对象。
清除阶段会将未被标记为“可达”的对象进行清理和内存回收。
-
分代回收
虽然标记-清除解决了循环引用的问题,但效率较低,且可能造成大量内存碎片。python还引入了分代回收提升垃圾回收的性能和效率。
所谓分代回收,即python按照对象的存活时间将内存分为若干代:年轻代(0代)、中年代(1代)、老年代(2代),并对不同代的对象采用不同的垃圾回收策略(如不同的垃圾回收频率)。此处有一个朴素的假设:存活时间越长的对象越不可能是“垃圾”。所以在垃圾回收频率方面:老年代<中年代<年轻代。
那垃圾回收器如何为对象分代呢?为对象维护一个年龄计数器,当对象的年龄计数超过一定阈值,则进行“代”的晋升。
gc.collect()提供了一个参数generation用于进行指定代的“垃圾”回收。
内存优化方式
-
手动管理内存来优化程序性能,例如使用del关键字手动释放不再使用的对象
-
控制资源的数量,如使用单例模式/多例模式限制类的实例化,尤其是耗时、耗资源的类(如实例化一个机器学习模型,见示例)
-
弱引用
-
延迟加载
-
使用__slots__减少类实例的大小
-
选用合适的数据结构
-
使用迭代器而非列表遍历
-
使用生成器
-
tuple比list节省内存
-
-
使用合适的算法
示例:通过单例减少内存资源消耗
假设在应用中需要加载参数量大小约为1G的深度学习模型用于完成某些预测任务或文本生成,由于资源消耗较多我们不希望对模型进行多次实例化,只希望进程中维持一份模型实例,单例模式在这种场景下就可以派上用场了。
最简单的做法是将模型的实例化在模块级别完成,相当于饿汉式的单例,如下所示:
model_name = "BAAI/bge-large-zh-v1.5"
model = SentenceTransformer(model_name)
假如我们还需要延迟加载,那么就需要使用懒汉式单例模式或者双重检测的单例模式。如下所示是一种基于双重检测的实现,ModelManager类会维护模型的实例且一个进程中对于同一个模型(按照name来唯一标识)最多只会维护一个实例。
class ModelManager:
"""
模型管理器
"""
_models = {}
_model = None
def __new__(cls, *args, **kwargs):
model_name = kwargs.get("model_name")
if model_name not in cls._models:
with _lock:
if not model_name not in cls._models:
cls._models[model_name] = SentenceTransformer(model_name)
return cls._models[model_name]
@classmethod
def get_model(cls, model_name):
return cls.__new__(cls, model_name=model_name)
def get_model(model_name):
model = ModelManager.get_model(model_name)
return model
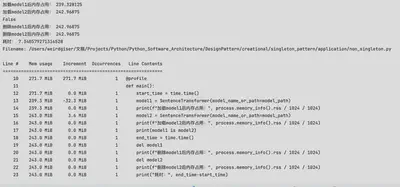
我们可以对比采用了单例模式加载多次模型和不采用单例模式加载多次模型的资源消耗。
不采用单例模式
import os
import time
from memory_profiler import profile
import psutil
process = psutil.Process(os.getpid())
from sentence_transformers import SentenceTransformer
model_path = r"/Users/weirdgiser/文稿/Projects/Models/languges/bge-large-zh-v1.5"
@profile
def main():
start_time = time.time()
model1 = SentenceTransformer(model_name_or_path=model_path)
print(f"加载model1后内存占用:", process.memory_info().rss / 1024 / 1024)
model2 = SentenceTransformer(model_name_or_path=model_path)
print(f"加载model2后内存占用:", process.memory_info().rss / 1024 / 1024)
print(model1 is model2)
end_time = time.time()
del model1
print(f"删除model1后内存占用:", process.memory_info().rss / 1024 / 1024)
del model2
print(f"删除model2后内存占用:", process.memory_info().rss / 1024 / 1024)
print("耗时:", end_time-start_time)
if __name__ == "__main__":
main()
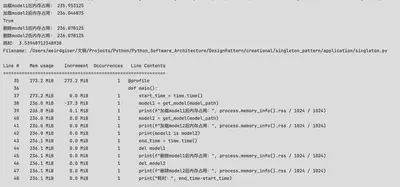
采用单例模式
import time
import os
import threading
from memory_profiler import profile
from sentence_transformers import SentenceTransformer
model_path = r"/Users/weirdgiser/文稿/Projects/Models/languges/bge-large-zh-v1.5"
_lock = threading.RLock()
import psutil
process = psutil.Process(os.getpid())
class ModelManager:
"""
模型管理器
"""
_models = {}
_model = None
def __new__(cls, *args, **kwargs):
model_name = kwargs.get("model_name")
if model_name not in cls._models:
with _lock:
if model_name not in cls._models:
cls._models[model_name] = SentenceTransformer(model_name)
return cls._models[model_name]
@classmethod
def get_model(cls, model_name):
return cls.__new__(cls, model_name=model_name)
def get_model(model_name):
model = ModelManager.get_model(model_name)
return model
@profile
def main():
start_time = time.time()
model1 = get_model(model_path)
print(f"加载model1后内存占用:", process.memory_info().rss / 1024 / 1024)
model2 = get_model(model_path)
print(f"加载model2后内存占用:", process.memory_info().rss / 1024 / 1024)
print(model1 is model2)
end_time = time.time()
del model1
print(f"删除model1后内存占用:", process.memory_info().rss / 1024 / 1024)
del model2
print(f"删除model2后内存占用:", process.memory_info().rss / 1024 / 1024)
print("耗时:", end_time-start_time)
if __name__ == "__main__":
main()
内存管理和调试工具
-
psutils
-
memory_profiler
-
tracemalloc