Python Sqlalchemy的一些使用技巧和问题
0x00 SQLAlchemy简介
ORM框架。
0x01 技巧与经验
根据建立好的数据表反向生成ORM Model
如果我们想针对已存在的数据表,使用ORM简化数据库操作,可以用sqlacodegen工具生成SQLALchemy格式的模型类,然后直接使用sqlalchemy进行ORM操作。考虑到有时候数据库密码可能含有特殊字符(如@),导致你直接在命令行执行操作时报符号相关错误,下面提供了一个简单脚本,根据已有的数据库信息从已有的表结构生成orm模型文件(包含模型类)。
import os
from pathlib import Path
BASE_DIR = Path(__file__).resolve().parent
from urllib.parse import quote_plus
from configparser import ConfigParser
db_config = ConfigParser()
db_config.read(os.path.join(BASE_DIR, "YOUR_CONFIG.conf"))
section_name = "YOUR_SECTION"
db_user = db_config.get(section_name, "MYSQL_USER")
db_name = db_config.get(section_name, "DB_NAME")
db_host = db_config.get(section_name, "MYSQL_HOST")
db_port = db_config.get(section_name, "MYSQL_PORT")
db_pwd = db_config.get(section_name, "MYSQL_PWD")
table_name = "YOUR_TABLE_NAME"
os.system(f"sqlacodegen--table {table_name} mysql+pymysql://{db_user}:{quote_plus(db_pwd)}@{db_host}:{db_port}/{db_name} > {table_name}.py")
查询大数据表时的优化策略
有时候我们需要对较大的数据表进行查询并处理其中数据,如果直接将大的查询结果集加载到内存中再依次遍历处理效率太低,可以考虑使用Query对象的yield_per(count)方法,一次只返回固定条数(count)的记录,节省内存开销。
# sqlalchemy.orm.query.py
# ......
@_generative
def yield_per(self, count: int) -> Self:
r"""Yield only ``count`` rows at a time.
The purpose of this method is when fetching very large result sets
(> 10K rows), to batch results in sub-collections and yield them
out partially, so that the Python interpreter doesn't need to declare
very large areas of memory which is both time consuming and leads
to excessive memory use. The performance from fetching hundreds of
thousands of rows can often double when a suitable yield-per setting
(e.g. approximately 1000) is used, even with DBAPIs that buffer
rows (which are most).
As of SQLAlchemy 1.4, the :meth:`_orm.Query.yield_per` method is
equivalent to using the ``yield_per`` execution option at the ORM
level. See the section :ref:`orm_queryguide_yield_per` for further
background on this option.
.. seealso::
:ref:`orm_queryguide_yield_per`
"""
self.load_options += {"_yield_per": count}
return self
空间数据类型支持
相关地址:
0x02 问题
Macbook Pro Apple芯片不兼容问题
有一个项目代码在windows中执行正常,但在macbook m2 pro机器上执行失败(sqlalchemy、mysqlclient、pymysql均为同一版本),异常跑出位置为MySQLdb.py的如下部分,导入动态依赖库失败。
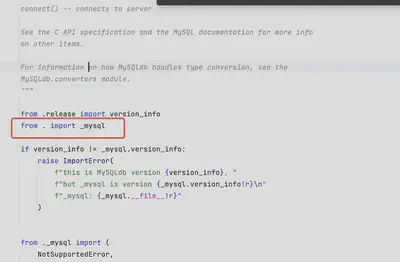
不少网友也遇到该问题(不仅有新版Mac处理器兼容问题,还有python版本问题,老版MySQLdb不兼容新版本python。(解决问题后,我找不到自己电脑报错的图了,也懒得去复现,引用一下查阅时网友贴出的报错信息)
解决方法:使用pymysql代替MySQLdb。
# 在项目sql相关代码运行前加入以下语句
import pymysql
pymysql.install_as_MySQLdb()