《重构-改善既有代码设计》(第二版)阅读笔记1
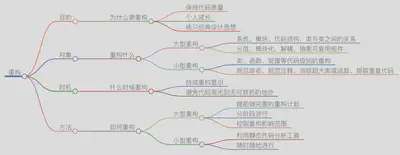
阅读目标
-
重构是什么?
-
为什么应该重构?
-
应该在什么地方重构?
-
如何进行重构??
-
有哪些重构名录经典案例?
Q:为什么要重构?
-
提升/保持代码质量
-
个人成长
-
练习、实践设计思想
Q:重构的目标对象是什么?
对什么进行重构?
- 大型重构:系统、模块、代码结构、类与类间关系
分层、模块化、解耦、抽象可复用组件
- 小型重构:类、函数、变量
规范命名、规范注释、消除超大类或函数、提取重复代码
Q:重构的时机
误区:代码烂到一定程度再集中重构
正解:持续重构,将重构作为开发的一部分
如同身体的健康需要持续地关注、保持,而非等到重病时才寻求治疗;代码的质量也应该持续关注和保持,而非胡乱堆砌代码到问题爆发才尝试集中解决。
如何判定代码是否需要解耦?
-
看修改代码会不会牵一发而动全身
-
可视化模块与模块间、类与类间的依赖关系,根据依赖关系图的复杂性判断是否需要解耦重构
Q:重构之“道”
如何给代码解耦?
基本思想
-
封装与抽象
隐藏实现的复杂性和易变形,提供稳定、易用的抽象接口
-
中间层
简化模块或类之间的依赖关系,让依赖关系从“网状”变成“星状”
-
模块化
基本设计原则
-
基于接口而非实现编程
-
依赖注入
无法将有依赖关系的两个类解耦成无依赖关系,但可以将强依赖关系解耦成弱依赖关系,让被依赖类具有可插拔、易替换的特性。
-
迪米特法则
小例子:报告生成功能代码的重构思路
假设应用A具有一个自助AI报告生成的功能,用户可以在平台中选择相应的数据源,并根据一定的筛选条件对数据源中的数据进行筛选,筛选完数据后用户点击“生成报告”按钮就可以触发自助报告生成的流程。
下面给出一段该功能的伪代码实现.其中payload是客户端发送请求时附带的参数,用于检索数据,并提供用户期望生成的报告主题、报告类型等信息。
# Implement 1
class GenerateTask:
def run(payload: dict) -> TaskResult:
# 校验参数
ok = check(payload)
if not ok:
return
# 检索用于报告生成的数据
data = ...
# FIXME ...判断数据量是否足够生成报告
# 实例化报告生成类
generator = ReportGenerator()
result = generator.generate(data)
# 保存结果
save_result(result)
return result
class ReportGenerateService:
def post(self, request):
payload = json.loads(request.body)
result = GenerateTask().run(payload)
return Response(data=result)
从简单原型的角度来看,上述伪代码的做法可以说五脏俱全,足以跑通功能,但是问题也很明显:
-
问题1: GenerateTask类承担了较多职责,内聚性不强,违背单一职责原则
-
问题2: GenerateTask对ReportGenerator类具有强依赖关系,不符合“松耦合”原则
上面描述的问题主要是从设计原则的角度评判代码设计存在的问题,从实践角度来评判,问题1会导致代码的可测试性较差,当测试人员想对自助生成报告这一包含多个流程的功能进行白盒测试时,难以对其中的每个子流程进行测试,而且即便测试完整的报告生成流程,由于难以将数据检索这一依赖数据库/网络的流程拆分开或数据mock,也会大大降低测试效率。
问题2会导致当我们想要引入一个新版本新特性(如支持用户自定义报告大纲)的报告生成类时,代码改造麻烦(需要修改GenerateTask.run方法,而这个方法的修改会导致其他本不该被影响的部分(数据检索、结果保存)也要被测试一遍。
基于上述分析,可以考虑对代码进行如下重构:
-
将报告生成中的数据检索参数校验、数据检索逻辑拆分出来
-
报告生成器ReportGenerator对象的创建放在GeneratorTask.run外,通过依赖注入的方式让GeneratorTask使用报告生成器对象的功能
根据上述重构思路,给出重构后的伪代码:
# Implement 2
class ReportConfig:
title: str
type: str
topic_word: str
keyword_list: List[str]
time_range: Tuple[datetime]
outline: ReportTemplate
class GenerateTask:
def run(report_config, data, generator: ReportGenerator) -> TaskResult:
result = generator.generate(report_config, data)
# 保存结果
save_result(result)
return result
class ReportGenerateService:
def post(self, request):
payload = json.loads(request.body)
# 校验参数
ok = check(payload)
if not ok:
return
# 检索用于报告生成的数据
data = ...
# FIXME ...判断数据量是否足够生成报告
# 实例化报告生成类
generator = ReportGenerator()
result = GenerateTask().run(report_config, data, generator)
return Response(data=result)
Q:有哪些开发场景实际上蕴涵了解耦的思想?
-
ORM框架
-
中间件
Q:如何发现代码质量问题
Checklist:
-
目录设置、模块划分、代码结构
-
是否遵循经典设计原则和设计思想?(SOLID、DRY、KISS、YAGNI、LOD)
-
设计模式是否合理运用?是否过度设计?
-
是否易扩展?
-
是否可复用
-
是否易测试
-
是否易读?
业务:
-
是否实现预期业务需求?
-
逻辑是否正确?是否处理异常情况?
-
日志打印是否恰当?
-
接口是否易用
-
代码是否存在并发问题?
-
性能是否有优化空间
-
是否有安全漏洞?
Q:如何保证重构的质量?
单元测试。
资源清单
-
英文电子书地址(官方): Refactoring: Web Edition
-
中文电子书地址: https://github.com/rabbit2002/Refactoring_2nd_ebook
经典的重构原则
-
如果你要给程序添加一个特性,但发现代码因缺乏良好的结构而不易于进行修改,那就先重构那个程序,使其比较容易添加该特性,然后再添加该特性。(P4)
-
重构前,先检查自己是否有一套可靠的测试集,这些测试集必须有自我检验能力。(P5)
-
重构技术就是以微小的步伐修改程序,如果你犯下错误,很容易便可发现它。(P8)
重构手法
-
提炼函数(Extract Function):将一块代码抽取成一个函数。(P7)
提炼时,考虑哪些变量会离开原来的作用域,哪些变量在函数中只是被使用而不会被修改,哪些变量会被修改。
-
以查询取代临时变量(P11)
-
……