后端实践:基于倒排索引构建搜索联想/提示服务(总览篇)
0x00 概念
搜索联想
“搜索”是现代互联网用户必须要使用的功能,但互联网内容如此之多,用户不一定知道有多少内容可以查询,通过搜索什么关键字才能获得想要的信息。因此,搜索联想是改进用户搜索体验的关键功能特性,好的搜索联想可以快速补全用户不完整的输入,纠正用户不小心打出的拼写错误,让用户更容易搜索到想要的内容,有时也可以引导用户去发现从未想过的但可能会感兴趣的内容。
通常来说,联想的切入点包括:前缀联想、按拼音联想、按热度联想、按关键字联想、多語言/字體聯想等,其中还要针对用户的错别字或者输入个性化差异做出纠正引导。比如:
-
用例1(字词纠错)
用户输入“中山工源”,实际上想搜索的是“中山公园”;
-
用例2(关键字补全,且不只是从前缀补全)
用户输入“达梦”,实际想搜索“武汉达梦数据库有限公司”
-
用例3(意图推断)
用户输入“武汉梧桐山”,实际上想搜“深圳梧桐山”
-
用例4 (基于拼音补全)
输入shenzhen或sz都需要联想到深圳,即按照拼音或者拼音首字母进行联想。
-
用例5 多語言、多字体支持
用戶用一種語言/字體查詢,返回標準字體的結果。比如在QQ音樂搜索繁體中文“倒數”,應該返回簡體中文的“倒數”。
倒排索引
对于搜索引擎系统而言,倒排索引是非常重要的组成部份。所谓倒排,是相对于正排来说的,通常说的正排指以文档为键,构建文档到关键字的映射关系;那么倒排就是以关键字为键,构建关键字到文档的映射关系,这种映射关系可以认为就是倒排索引。简单形象的示例如下:
正排索引表:
文档1-->{词1, 词2, ..., 词n}
文档2-->{词1, 词2, ..., 词n}
倒排索引表:
词1-->{文档1, 文档2, ..., 文档m}
词2-->{文档1, 文档2, ..., 文档m}
倒排索引的优势在于可以快速查询某字词对应的文档/包含某字词的文档;正排索引的优势在于确定单个文档中有哪些关键字词。
0x01 实践
倒排索引构建
倒排索引的基本原理是空间换时间,底层通过Key-Value的数据结构来维护索引词与文档的映射关系,可以认为Key是字符串类型(string),Value是一个可迭代对象(Set/List)。基于上述原理,可以确定倒排索引构建过程如下:
-
遍历文档集合,对于每一篇文档,进行如下处理;
-
针对单一文档,计算出所有可能的Key,得到一个Key的集合。
此处的Key可以是文档分词后得到的词集合,也可以是文档中句子的前缀/后缀等,或者分词的拼音,具体如何可根据联系需求确定。
-
建立每一个Key到文档的映射关系,这一步可以将文档名或文档ID视为Value
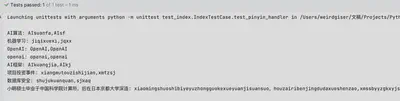
示例:拼音索引
对于待处理词,通过语言模型/拼音词典输出词对应的拼音及拼音首字母组合,然后即可构建可构建拼音倒排索引类似如下结构
......
jqxx --> 机器学习
jiqixuexi --> 机器学习
AIkj --> AI框架
......
示例:关键词索引
简单起见,此处示例的关键词指“分词”后的结果,当然实际应用时可以考虑采用一些关键词抽取的方法(如TextRank)抽取关键词。

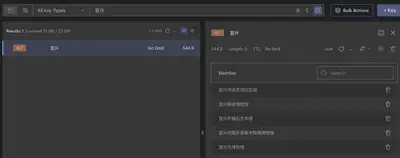
倒排索引存储
最简单的存储方式,就是在内存中通过HashMap存储,Key为索引词(可以是文档关键字、拼音全拼、拼音首字母等),value为“文档”(待联想对象)。
如果数据量大,考虑到全量倒排索引构建时间较长,可以通过内存数据库(如Redis)或者文件型数据库存储倒排索引,并进行一定的压缩。
-
以Redis为例,可使用Set数据类型存储“文档”
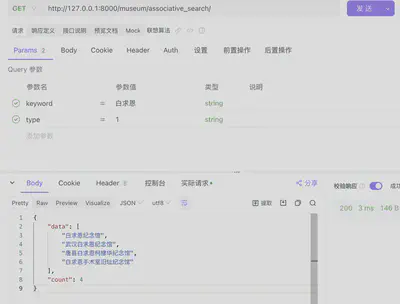
实际测试
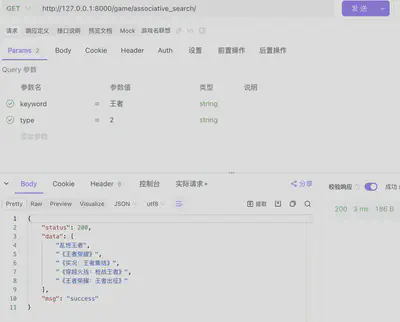
- 按关键词“王者”联想检索游戏
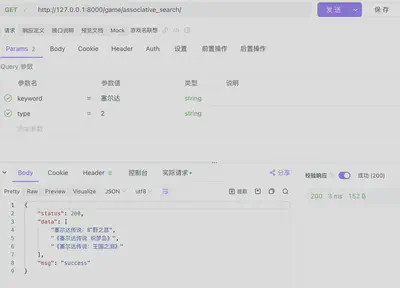
- 按关键词“塞尔达”联想游戏
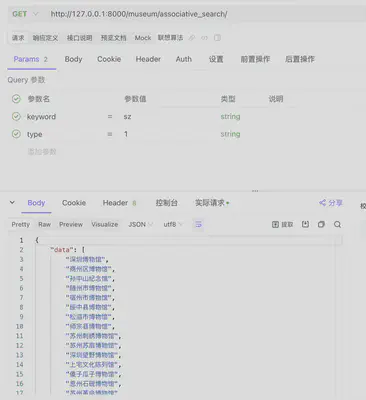
- 按拼音首字母“sz”联想博物馆
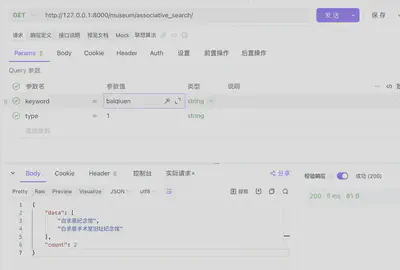
- 按拼音“baiqiuen”联想
- 按关键字“白求恩”联想