文本匹配技术调研与实验--以企业名称识别为例
前言
对文档进行标签化/分类是很多现代系统的基本功能,如新闻类平台对新闻主题进行分类、商业智能领域需要从新闻、专利、招投标、行业研报等文档中识别出企业实体信息并对数据建立关联关系。
方法
- 基于规则的字符串模式匹配:判断文档中是否存在子串(关键字),并且需要考虑同一关键字的多种表达(如商汤科技简称商汤,又可称sensetime)
- 实现1:子字符串存在性判断
- 实现2:正则表达式
- 命名实体识别:识别组织型实体
- 对文档集合构建倒排索引,通过判定索引词是否包含指定关键字或是企业实体进行数据匹配
实现
经典方法:字符串模式匹配
基于in操作符
8线程情况下,处理10个新闻正文匹配,耗时9s
基于正则表达式
暂略
正则表达式与in操作符效率对比
子串查找方面,in操作符效率更高。
命名实体识别:企业实体识别
先测试现成NLP工具库spacy的效果
基于spacy进行命名实体识别
准备工作
安装中文模型,详情可参考文档Chinese · spaCy Models Documentation:
可通过如下命令安装模型
python -m spacy download zh_core_web_sm
python -m spacy download zh_core_web_lg
python -m spacy download zh_core_web_trf


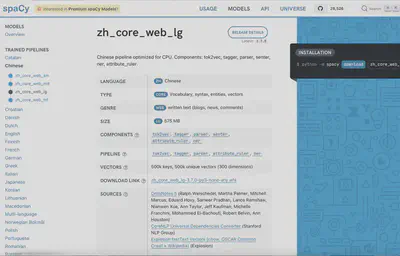
可以查看模型的特征(训练数据集特征、适用任务、特征向量维度、模型大小等)

基本测试
用例:
华为爱上了苹果,小米吃醋了,vivo和oppo也不甘示弱,纷纷表示要超越华为,成为中国最大的手机厂商.
商汤科技,旷视科技,旷视科技有限公司认识宝莱特,宝莱特公司说这是一个测试用例,可以给外包公司做,自己公司可以不考虑这些事项。
企知道也不知道,企查查说他知道,灵犀数据说他也知道,但是他们都不知道。文因说文因互联是一个很好的公司,可以给他们做一些事情。
但韶华为了韶华科技,韶华科技有限公司,也这么说商汤集团。但平安不这么看。
- zh-core-web-lg

- zh-core-web-trf

针对上述例子,对比一下zh-core-web-lg、zh-core-web-trf模型的企业实体识别效果:
| 模型 | zh-core-web-lg | zh-core-web-trf |
|---|---|---|
| 实体名称错误 | oppo、科技有限公司 | |
| 实体类别错误 | 宝莱特 | |
| 未命中 | 平安、韶华科技、文因互联、企知道、灵犀数据 | 小米、文因互联、企查查、企知道、灵犀数据 |
可以看到,两个模型均存在一些问题。
可否通过微调模型或结合规则提升模型对企业实体识别的召回率
TODO