Text2sql技术工具调研与框架设计
工具
DB-GPT-Hub:基于LLM的Text-to-SQL解析框架
NL2SQL: Text2SQL 语义解析数据集、解决方案、paper资源整合项目
https://github.com/BeachWang/DAIL-SQL
Text2SQL: A Powerful Tool for Querying Databases with Natural Language
功能需求分类
基本需求
-
单数据库、单数据表
-
单数据库、多数据表
-
多数据库、多数据表
安全需求
-
防止自然语言触发的SQL注入
需要sql注入检测、过滤机制
-
防止自然语言生成的DDOS数据库攻击/执行高耗时语句
需要熔断机制
应用场景示例
用户输入意图:
离西丽站最近的50个博物院,生成pgsql,xxxx(prompt)
生成SQL:
WITH station_location AS (
SELECT ST_GeomFromText('SRID=4326;POINT(114.2 22.37)', 4326) AS location -- Replace x_coord and y_coord with actual coordinates
)
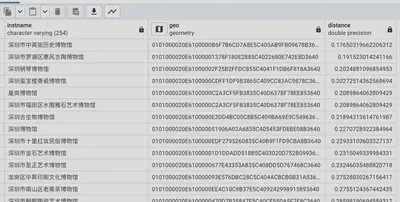
SELECT m.instname, m.geo, ST_Distance(m.geo, s.location) AS distance
FROM museum m, station_location s
WHERE ST_DWithin(m.geo, s.location, 500)
ORDER BY distance ASC
LIMIT 50;
执行查询:
原理
-
语义解析:将自然语言输入解析成结构化数据,表示查询中涉及的概念及概念间关系
-
实体识别:表名、列名、值
-
语义匹配:将自然语言中识别出的实体与数据库中的实体进行匹配
-
查询生成:生成对应的SQL语句
语义解析
语义解析时,除了从用户输入中对概念实体进行识别,可能还需要精确数据(如用户希望查询或查询条件需要精细的数据:xxx名称、坐标地点、身份证号码等)查询,精确数据不一定在大模型训练数据集中存在,所以可能需要接入私有数据库或借助第三方数据API进行精细数据获取,其中会涉及用户意图细节补全。
实现思路
第一步:简单考虑,针对给定的表结构提示,针对单表进行text2sql查询
第二步:给定数据库,针对数据库内表结构进行text2sql
第三步:给定数据库连接(只读),模型自动学习数据库表结构,生成对应prompt,进行text2SQL
第四步:指定多个数据源,模型需要判断查询哪些数据源,…。
拓展:并行调用
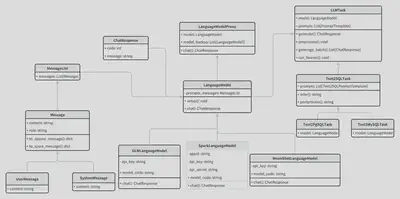
代码骨架设计
-
模型(大语言模型)
-
流水线(对话循环)
-
消息
-
提示模板
-
任务(text2SQL, ……)
-
配置
-
测试用例
-
通用工具(日志、数据库驱动、搜索引擎)
辅助工具
-
搜索引擎
bing search api
示例
基本测试
GLM4
- 大模型是否可以判断用户问题是否“可解”
question: 世界上生与死的距离是否大于1公里? code: 1
answer: 由于这个问题并没有直接或间接地表明需要查询数据库,也没有提供具体的数据库表结构信息,因此我无法生成相应的Postgres查询语句。根据您给出的规则,我应该返回:
0
question: 屏幕前的你和屏幕前的我现在是否正在熬夜? code: 1
由于这个问题并不包含任何直接的查询意图,我无法生成一条Postgres查询语句。因此,根据您的要求,我会返回0。
0
- 大模型是否可以判断现有库表结构对回答用户问题的可支持程度
从下面示例可以看出,虽然大模型会对作出假设给出相应的查询语句,但其也会根据给定数据库表结构来判断问题实际是否能被现有数据支持。
question: 南京路和北京路距离有多远? code: 1
根据用户提出的问题,似乎用户希望得知的是两个地点(可能是以“南京路”和“北京路”命名的道路)之间的距离。但是,由于没有提供具体的表结构信息,我们无法直接生成一条准确的PostgreSQL查询语句。
如果假设用户是在请求城市中具体命名的道路之间的距离,并且我们的数据库中有相关道路的地理信息,那么理论上我们可以使用postGIS的函数来计算这两点之间的距离。
以下是一个假设性的查询语句,它假定:
- 数据库中有一个名为`roads`的表,其中包含道路的名称和地理数据。
- `geom`列包含的是postGIS支持的地理数据类型,如`LINESTRING`。
- `name`列包含道路的名称。
查询语句如下:
```sql
SELECT ST_Distance(
ST_Transform(
ST_SetSRID(
ST_MakePoint(
ST_StartPoint(geom)::text, -- 假定geom是LINESTRING类型,获取起点
ST_EndPoint(geom)::text -- 获取终点
),
4326), -- 设置为WGS84坐标系
900913), -- 转换为米制坐标系,适合计算距离
ST_Transform(
ST_SetSRID(
ST_MakePoint(
(SELECT ST_StartPoint(geom)::text FROM roads WHERE name = '北京路'), -- 假定找到北京路的起点
(SELECT ST_EndPoint(geom)::text FROM roads WHERE name = '北京路') -- 假定找到北京路的终点
),
4326),
900913)
) / 1000 AS distance_in_km
FROM roads
WHERE name = '南京路'; -- 假定找到南京路的起点和终点
如果数据库中不存在这样的表和列,或者用户的问题实际上与数据库查询无关,那么按照您的要求,应当返回1,因为现有的信息不足以支持用户的查询需求。
由于用户的问题不是很明确,这里我假设用户确实是在查询数据库中的信息,因此提供了上述查询语句。如果实际情况下用户的问题并不涉及数据库查询,正确的回应应当是:
1
表示现有数据库表结构不足以支持用户的查询需求。
- 大模型生成的SQL是否合理
question: 天安门和地安门是否在同一个城市 code: 1 answer: 基于提供的参考信息,我可以判断天安门和地安门位于同一个城市,即中国的北京市。
以下是针对用户可能的查询需求而生成的一条PostgreSQL查询语句(假设数据库中有一个名为historic_buildings的表,且该表包含表示建筑名称和所在城市的字段):
SELECT COUNT(*)
FROM historic_buildings
WHERE name IN ('天安门', '地安门') AND city = '北京市';
如果天安门和地安门的相关信息确实保存在数据库中,并且表结构如假设所述,上述查询将返回2,表示这两个建筑都位于北京市。
但是,如果数据库中并没有相关表或者字段来支持查询这两个建筑的信息,那么根据您的要求,应返回1。而如果用户输入的信息中不存在查询意图,则应返回0。
由于这里是假设性回答,并且没有具体的数据库结构信息,以上查询只是根据用户需求的可能情景而构造的示例。实际情况中,需要根据数据库的具体结构和内容来确定查询语句。