基于LLM的自动化报告生成——舆情分析报告
目录
0x00 项目架构
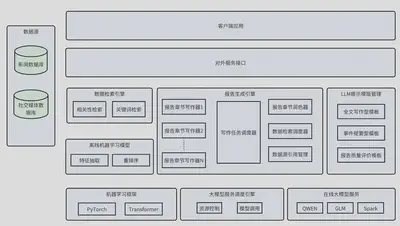
-
数据检索引擎
给定查询词及其它查询参数,查询出最相关的数据(新闻)。
-
报告生成引擎
根据给定的报告提纲(含报告主题、各章节标题、也可包含用户对各章节的写作偏好)及其它参数(如偏好报告风格),调用写作器、润色器进行报告撰写
-
大模型服务调度引擎
对第三方大模型服务提供商的模型进行统一调度。
-
……
0x01 核心数据结构
报告提纲树
提纲实际上是一棵树,根节点为以报告名称命名的节点,其下面的子节点为子章节,每个子章节又分别是独立的子树。
-
报告章节节点
class ArticleSectionNode: """ ArticleSectionNode 用于处理文章的章节,包括存储章节正文、定义章节写作偏好. """ def __init__(self, section_name: str, content=None): """ section_name: 字符串形式的章节名称, e.g. 报告观点, 近期动态, etc. content: 章节正文内容. 可以是字符串或其它数据结构,取决于你的选择. """ self.section_name = section_name self.content = content self.children = [] self.preference = None def add_child(self, new_child_node, insert_to_front=False): if insert_to_front: self.children.insert(0, new_child_node) else: self.children.append(new_child_node) def remove_child(self, child): self.children.remove(child) class IndustryAnalysisArticleSection(ArticleSectionNode): def __init__(self, section_name: str, content=None, description=None, parent_name=None, filter_words=None, query_words=None): super().__init__(section_name, content) if query_words is None: self.query_words = [] else: self.query_words = query_words self.description = description self.parent_name = parent_name if filter_words is None: filter_words = [] self.filter_words = filter_words -
报告提纲树
class Article(ABC): def __init__(self, topic_name): self.root = ArticleSectionNode(topic_name) class IndustryAnalysisArticle(Article): def __init__(self, topic_name: str, description: str): super().__init__(topic_name=topic_name) self.description = description self.summary = "" def __repr__(self): return f"{__class__}({self.root.section_name}, {id(self)})" @timer def to_string(self) -> str: """ 将文章以字符串形式输出。 """
信息表
- 舆情信息
用于维护每条新闻的基本信息(title、abstract等)和便于检索的信息(特征向量、标签)
- 舆情信息表
用于维护一篇报告所依赖的基础数据集,实现数据检索方法(离线、也可以有在线搜索)
class NewsInformation(Information):
def __init__(self, url, description, title, meta=None,abstract=None,tags: Optional[List[Tag]]=None):
super().__init__(url, description, title, meta)
self.abstract = abstract
self.tags = tags if tags is not None else []
self.encoded_title = None
self.encoded_abstract = None
def add_tag(self, name, tag_type=None):
self.tags.append(Tag(name, tag_type))
@property
def content(self):
return self.description
@property
def tag_set(self):
return set(tag.name for tag in self.tags)
def get_tags(self, type=None):
if type is None:
return set(tag.name for tag in self.tags)
return set(tag.name for tag in self.tags if tag.type == type)
def contains_keyword(self, keyword_list, title_only=False):
if title_only:
text = self.title
else:
text = f"{self.title}{self.content}"
match_result = TextMatchUtil.contains_keywords(text,
keyword_list=keyword_list)
if match_result.count > 0:
self.tags = [Tag(word) for word in match_result.matched_keywords]
return True
return False
class NewsInformationTable(InformationTable):
def __init__(self, news_collection: List[NewsInformation], filter_words=None, encoder=None):
super().__init__()
if filter_words is None:
filter_words = []
self.news_collection = news_collection
self.title_to_info: Dict[str, NewsInformation] = NewsInformationTable.construct_title_to_info(self.news_collection)
self.filter_words = filter_words
self.encoder = encoder
def __len__(self):
return len(self.title_to_info)
def retrieve_information_plus(self, queries: Union[List[str], str], search_top_k: int=20,topic=None,
similarity_threshold: float=0.4, filter_words: List[str]=None,
remove_duplicated=False) -> List[NewsInformation]:
pass
0x02 核心流程
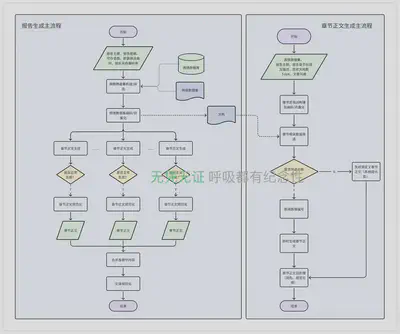
0x03 效果示例及问题
检索效果
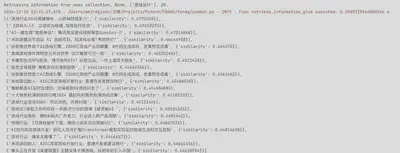
几种检索策略对比
-
基础策略:向量语义检索
-
向量检索结合标题关键词过滤
-
向量检索结合标题+正文关键词过滤
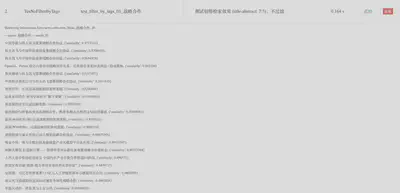


报告结果效果
- 基于事实(受限于参考数据源的权威性)写作,观点附带引用
- 具有两种报告风格:全文型(篇幅较长)、事件提要型(较为简洁、事件列举)
- 并行生成报告,效率高

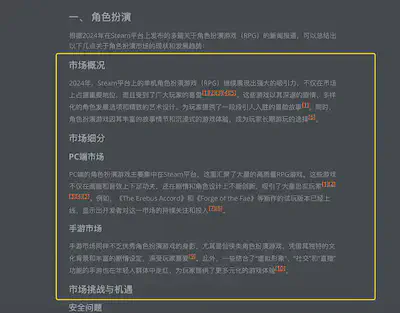
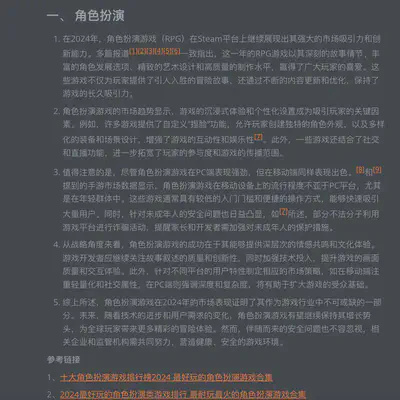
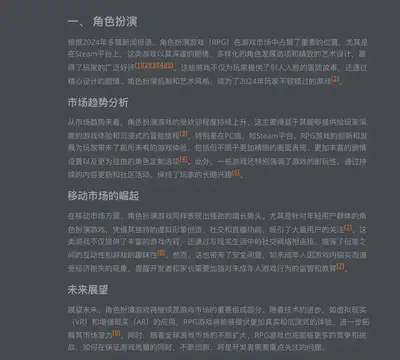
全文类型报告示例
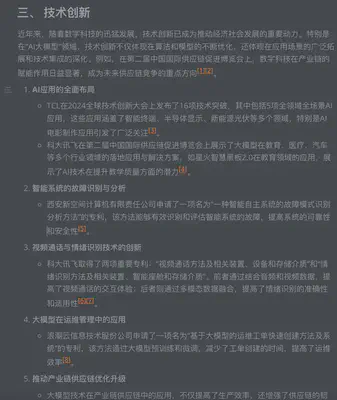
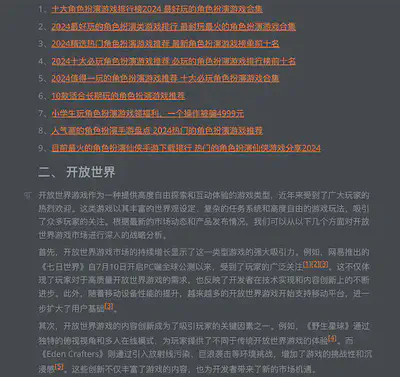


事件提要类型文章

问题
生成模型的问题
Q:大模型执行违背指令
如通义千问qwen-plus模型,如果prompt中显式提示不要输出markdown格式,模型反而会输出大量markdown格式文本。
- **格式要求:** 使用纯文本格式,不得包含任何Markdown或其他格式符号。
如果不额外提示不输出markdown,模型反而在大部份情况下不会输出markdown。输出示例如下图所示:

类似地,如果prompt中提示模型不要通过序号分点做法,模型反而会输出大量序号。示例如下:
直接提示模型分段输出,模型反而不输出序号:
说明qwen-plus系列模型(也包括qwen-max-0919)目前对于输入指令中“逻辑非”的理解也处理不到位。
可以通过规则的方式缓解这一问题,比如通过如下正则表达式:
@classmethod
def clean_markdown(cls, content):
content = re.sub(r'^#{1,6}\s*[\u4e00-\u9fa5、\w]*', '', content, flags=re.MULTILINE)
return content
检索模型的问题
Q:部分数据检索相关性较低
采用BAAI/bge-reranker-v2-m3,效果较差

采用bge-large和bge-m3效果较好,但难以通过阈值排除一些不太相关的信息。
bge-large-zh, 查询“政策法规”

bge-m3, 查询“政策法规”

bge-large-zh, 查询“DLC”

输入数据质量问题
Q:数据源信息量少
-
部分新闻完全是图片,对于文本模型而言这类输入没有什么信息量。
-
部分网络新闻在获取时包含较多噪音
Q:输入信息不全面
-
输入给LLM的数据主要是新闻摘要,如果新闻摘要本身反映原文的信息较少,会影响报告效果(用户兴趣信息召回率)
实践中,有一些新闻正文本身就是信息罗列型的,可能每一段都是不应被忽略的信息,大部份重点关注头部和尾部的摘要算法处理此类文本效果不理想。示例数据和结果如下:


A: 若模型可处理上下文长度足够长,可考虑输入正文或更长的摘要以提取更详细的信息
基于新闻正文生成的报告:

0x04 外部资源
特征抽取模型
- bge-large-zh
- BAAI/bge-m3
- jina-embeddings-v3