「论文阅读」The Anatomy of a Large Scale Hypertextual Web Search Engine
Abstract
在这篇文章,作者提出了一个能够充分利用超文本结构特征的大规模搜索引擎的原型系统:Google。Google的设计目的是爬取互联网上的内容并建立高效的索引结构,以便用户从中获得远超已有的搜索引擎的搜索体验:得到更令人满意的搜索结果。文章还公开了一个超过2400万的包含网络超链接和全文的原型数据库。
摘要
建立搜索引擎是一项具有挑战性的工作,需要用海量可分的词汇对海量的网页数据建立索引,用于回答每天百万千万级的搜索。尽管网络页面的大规模搜索引擎十分重要,当时却很少有学术研究对搜索引擎进行针对性研究。而且,随着技术进步和网络页面激增,构建一个网络搜索引擎已于三年前(以文章发表日期算)非常不同,本文对所提出的大规模网络搜索引擎(Google)进行了详尽的描述–截止文章发表日期作者所了解到的最详尽的描述。
除了在数据量级上解决传统搜索技术的问题,本文还提出了一种新技术:使用超文本中附带的信息优化搜索结果。本文解决了如何利用超文本中的附加信息来构建具有实用价值的大规模系统的问题。文章还关注如何有效处理不受控制的任何人都可以随心所欲发表内容的超文本集合。
引言
Web为信息检索领域带来了全新的挑战。Web页面中信息的量级增长迅速,同时Web的新用户也在与日俱增。人们可能基于一个带有链接的图来进行网上冲浪,这种链接图往往由具有一定权威性的人或组织维护(比如Yahoo!或者搜索引擎);人们维护一个覆盖很多流行主题的列表尽管有效但主观并且构建成本和维护成本高昂、提升缓慢并且无法覆盖所有专业领域的主题(只有内行人才能懂)。依赖于关键词匹配的自动化的搜索引擎通常返回了太多低质量的搜索结果,而且雪上加霜的是,一些广告商为了获得人们的注意专门采取策略来误导自动化搜索引擎。作者构建了一个大规模搜索引擎用于解决现有系统的大多数问题,充分利用超文本中存在的结构信息用于提升搜索结果质量。作者将其系统命名为Google,因为这是googol(10的100次方)的一个常用拼读方式,这与作者希望构建超大规模搜索引擎的愿景相适应。
1.1 网络搜索引擎的规模化: 1994-2000
搜索引擎技术必须要进行明显地规模化才能跟上Web的增长。1994年第一代Web搜索引擎,The World Wide Web Worm(WWWW)对110000条网页和网络公开文档进行了索引;1997年11月,顶级搜索引擎(WebCrawler)声称对两百万乃至1亿个网页文档进行了索引(数据源自Search Engine Watch );可以预见到2000年,对Web的全面索引将会到达十亿的级别。同时,查询的量级也会进行可观的增长。1994年3~4月份,WWWW每日面临约1500条查询;1997年11月,Altavista声称其每日处理约2000万条查询。随着互联网用户的增加和检索搜索引擎的自动化系统的增多,很可能到2000年最顶级的搜索引擎将要每日处理十亿级的查询。Google的目标就是要引入高效的搜索引擎技术,解决上述搜索质量、搜索规模相关的问题。
1.2 Google:随web扩张
创建一个能够满足今日Web规模的搜索引擎会面临如下挑战:
-
快速的爬虫技术用于获取Web文档并保证其处于最新状态;
-
需要高效地利用存储空间来存储索引和文档本身
-
索引系统必须能够高效地处理百千兆字节的数据
-
查询必须被快速的处理,每秒处理成百上千
上述任务随着Web的扩张会变得越来越困难,尽管硬件性能和开销已经有了了不起的提升,可以部分地解决上述困难,但我们还是能发现一些明显异常如硬盘搜索空间和操作系统鲁棒性方面的问题,在设计Google时,作者已经考虑了Web的增长和技术的变迁。因此Google被设计成能够适配极大规模的数据集。更进一步考虑,作者期望索引和存储文本/超文本的成本能够逐渐下降。
1.3 设计目标
提升搜索质量
1994年,一些人认为:完备的索引可以使得我们轻易地找到任何内容。根据Best of the Web 1994,最佳的导览服务应该让寻找几乎所有web内容变得简单。然而,到1997年的Web与1994年截然不同,任何用过搜索引擎的人都很乐意为这一事实作证:索引不仅仅是影响搜索结果质量的唯一因素。“垃圾结果”(Junk results)充斥着互联网,阻碍用户找到自己感兴趣的结果。事实上,在1997年11月,四大商业搜索引擎中仅有一家搜索引擎能在搜索结果的前十条里找到自己的名字,导致这一现象的主要原因是索引中文档的数量已经增长到超乎预期的量级,但用户对于文档的阅读容量并不会提高,人们还是倾向于仅仅浏览前十条搜索结果。因此,随着文档数量的增长,我们需要能够返回高质量搜索结果的工具,高质量意味着返回的内容是尽可能与用户搜索意图相关。我们希望我们返回的相关的(relevant)搜索结果包含了最好的文档,这些文档要区分于那些轻微相关的文档。这一点十分重要,我们要尽可能提高“高质量“搜索结果的召回。
有部分研究已经表明超文本的信息有助于提升搜索质量,链接结构和链接的文本也提供了大量信息用于判定文档的相关性和质量,Google同时利用了链接结构(link structure)和锚文本(anchor text)。
相关文献
学术型搜索引擎研究
除了规模的与日俱增以外,Web变得极度商业化。在1993年,有1.5%的Web服务是.com域名,到1997年这个数字增长到60%。同时,搜索引擎从学术领域逐步走向商业化。到现在为止(1997年),大多数搜索引擎都由公司掌控,仅仅披露了少数技术细节,这导致搜索引擎技术成了一个黑箱艺术并且主要服务于广告。有了Google,我们就有了更强的目标,那就是推动搜索引擎在学术领域的发展,增加人们对这项技术的认知。
另一个重要的设计目标就是构建一个大多数人可以实际使用的搜索引擎。“可用性”是非常重要的,因为我们认为大多数研究需要利用现代Web系统中的数据,但现有的搜索引擎因为商业价值的考虑不免费提供数据,导致用户的数据获取需求难以满足。
我们的最终的设计目标是构建一个架构,可以支持对大规模Web数据的前沿研究活动。为了支持前沿研究,Google将爬取的所有文档以压缩的形式存储。设计Google的主要目的之一是构建一个环境,让其他研究者可以快速地参与研究、处理海量的Web数据并生成有趣的结果。已经有很多论文基于Google生成的数据库,并且这一趋势还在蔓延。另一个目标就是建立一个太空实验室一样的环境,让研究者甚至学生可以基于我们的大规模Web数据开展有趣的实验。
系统特性
Google搜索引擎能生成高质量的搜索结果得益于两个重要特性:首先,充分利用Web的链接结构来计算每个Web页面的质量排序评分,这种排序称为PageRank。其次,Google利用链接来提升搜索质量。
-
PageRank:bring order to the Web
-
Anchor text
系统设计
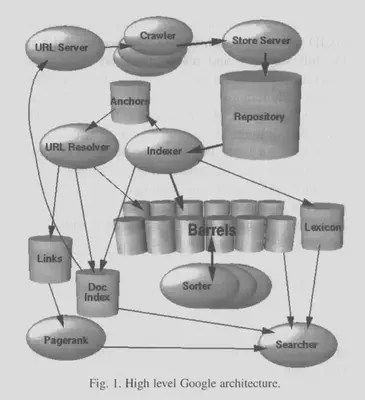
花絮
对比现有知名搜索引擎的用户体验
- Bing
- Baidu

- 360
- Sougou

高下立判。