「论文阅读」基于倒排索引和字典树的站内搜索引擎的设计与实现
Abstract
随着互联网的不断发展,快节奏的生活,人们对更好的用户体验的追求, 搜索的长时间等待变得让人无法忍受。如何获得更快的搜索、更好的搜索结果、 更符合用户心理的推荐成为很多网站、手机应用的痛点。本项目意在通过建立 倒排索引加快搜索,使用字典树结构快速找到联想词,二者相结合的方式提供 良好的搜索体验。完成一个独立的站内搜索引擎,使得项目可以快速的移植到 不同的系统中,提高开发速度,降低开发成本。本项目主要完成一个轻量级站内搜索引擎。系统主要分为两大部分:第一 部分为全文索引引擎,主要负责从数据源建立倒排索引、以有效的格式保存索 引、增量更新索引、索引的压缩、搜索排序等功能; 第二部分主要为拼音搜索 引擎,主要完成关键字检索、模糊查询、拼音联想等功能;此外完成系统对外 的相关接口。主要的工作内容是:独立完成对整个站内搜索引擎需求分析、系 统设计、系统实现以及测试等工作;完成了系统的 8 大核心功能模块,2 个辅 助模块以及所有对外的接口。具体包括(1)文档数据源获取,(2)倒排索引的建立 与压缩,(3)倒排索引更新,(4)倒排索引的查找,(5)搜索排序,(6)拼音转化功能 的实现,(7)拼音搜索 Trie 建立,(8)拼音联想词的查找,以及辅助功能如高亮显 示、相关推荐等功能。
论文总结
实现效果
通过结合倒排索引和字典树加快搜索,站内搜索响应时间0.02s,拼音联想响应时间2ms。项目应用成果展示:百度APIStore的官网站内搜索
系统模块功能
全文搜索引擎
-
基于数据源建立倒排索引
-
倒排索引保存
-
倒排索引增量更新
-
索引压缩
-
搜索结果排序
拼音搜索引擎
-
关键字检索
-
模糊查询
-
拼音联想
主要特性
-
搜索性能
预先建立倒排索引,搜索时通过索引找条目,相比传统数据库全文搜索,更快。
-
可移植性
独立的搜索服务,通过序列化数据进行通信,可快速移植到不同的产品项目中。
-
调用灵活性
RPC
-
用户体验
拼音联想、高亮摘要显示
可拓展性/可用性/可移植性设计
-
基于磁盘排序的归并算法
-
cidxHit-算法压缩
-
BM25-相关性计算
-
字典树-拼音联想
研究现状调研
传统信息检索系统采用的技术:
-
关键词匹配
-
修改数据库索引设计,如使用全文索引(Full-Text Index Technique)
瓶颈:TB级数据库的出现、用户查询时无法有效提供关键字导致依靠数据库关键字匹配的检索系统无法满足用户需求。
搜索引擎的分类
-
目录式搜索引擎
-
全文搜索引擎
通过字典中的检索字表查字,按字和词检索;如何建立索引:扫描文章中的每一个词/字,记录该词/字在文章中出现的位置和次数,写入对应的文件中。
-
元搜索引擎(Meta Search Engine)
全文搜索引擎现状
核心思想:通过字典表中的检索字表查字。
智能检索:分词词典、同义、同音词典、主题词典、相关同级词典、上下位词典检索给予用户智能提示。
全文检索对比数据库查询
| 全文检索 | 关系型数据库 | |
|---|---|---|
| 优点 | 搜索速度快 | 事务性强 |
| 易于拓展,支持不同数据源类型 | 对精确小量查询快 | |
| 支持相关排序:可制定特定排序方式进行相关性排序 | ||
| 缺点 | 索引需要大量额外空间、操作;需要定期维护索引 | 大文本全文搜索经常超时 |
关键技术概述
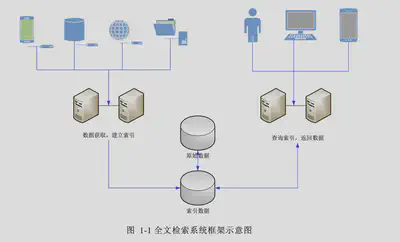
-
后台过程:索引创建引擎
从文本中获取字、词相关信息,按指定方式创建索引
-
前台过程:根据用户的查询请求,搜索指定索引,返回结果
站内搜索系统具体设计与实现
基础框架
-
NLPC(自然语言处理云平台)
集成分词、词性标注、专名识别、term 重要性、plsa(pLSA 主题模型-概率潜在语义分析)、语义表示、query 解析和情感分析等服务。
-
Baidu-RPC 框架
支持不同语言的远程调用。
需求
搜索系统交互逻辑
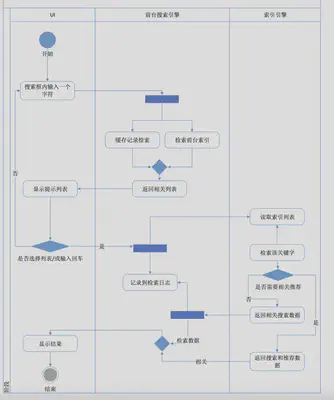
拼音搜索引擎需求
全拼音、汉字+拼音、首字母组合
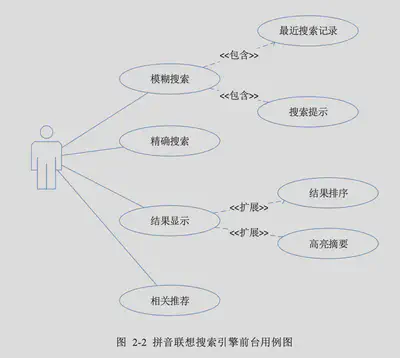
站内搜索交互核心需求表:

后台检索引擎需求
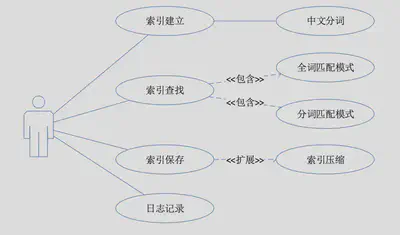
索引引擎核心功能需求分析表:

文献
-
陶晓鹏. 面向(中文)全文数据库的全文索引的研究[D]. 复旦大学, 1999
-
吕晓旭. 基于倒排索引的关系数据库全文检索查询效率研究[D]. 北京工业
大学, 2009
- 史亮. Web 搜索引擎索引压缩与合并技术研究[D]. 中国科学院大学, 2013